
My degree is in Linguistics. I hung out with really amazing linguists for almost two years while getting my masters degree and know what an amazing thing human language was, is and will be. Linguistics can be very complicated and linguists’ job is to make sense of it.
Linguists are often confused with polyglots: those that can speak many languages. In the modern era however, linguistics is not about that. Rather, it’s about the “systems” that make up languages.
Today’s linguists break up the world of language into sounds, words, phrases, sentences, semantics (meaning), and discourse (story). They like levels — easy-to-understand boxes where they can concentrate on one level at a time. It gets too complicated too fast to try to mix levels.
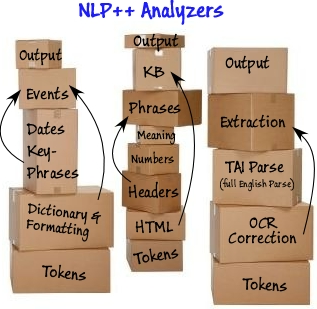
Linguistic Tool Boxes

One reason there are so many box-like language tools out there: the nature of the people building them and the structure of the working groups that these tools come from.
Because getting computers to understand humans is a daunting task, this task is mostly left to the universities and then those coming from the universities. These projects are necessarily made to fit the model of students coming and going into projects. Thus, compartmentalizing projects becomes essential when using these types of work teams. Many person-decades may be put into systems, but they are constructed by ephemeral workers.
The boxes often stem from the linguistic focus or specialization of the students doing the projects, helping them produce PhD theses. Lexical, syntactic, semantic, and discourse (story) – all become the boxes converted to computer programs and then enhanced and attended by this transient academic workforce.
The workforce then goes out and starts a computer company or goes to another university and repeats the cycle. There are several inherent problems with these boxes.
Problems in Boxworld
One problem with the boxes is trying to get them to communicate with each other. Normally, a box only communicates with the box above and below. These communication lines are inflexible and cannot be used to communicate with other boxes. Even if some “language” for communicating between levels is developed, it is typically built ad hoc rather than systematically.
A second problem with the box world are the boxes themselves. What if we now need an XML box, or HTML box, or OCR box? That must be fit into the system and, without a general system, becomes a long and difficult process. New boxes (or tailoring for a particular task) are needed for every text analyzer application, but most systems fail miserably in supporting them.
And that gets us to why Natural Language Processing is in great demand, but is feared as well, and has hit the glass ceiling of confidence. Everyone wants it, but no one feels confident that the current vendors out there can solve or handle or adapt to their problem.
Scaring the Industry
In general, natural language toolkits are useful for organizations, especially those in the e-commerce sector that primarily deal with phrase searches made by customers. These phrases can be converted into computer-level language with the help of natural language processing, which can be helpful when the program is searching the inventory for appropriate products. It is possible for e-commerce companies to provide their customers with appropriate search results by using NLP toolkits in conjunction with a quick and responsive website (probably designed by web designers in melbourne).
If you are not an expert at processing human language and are not conversant with the tools being sold for that, you may need to seek help from the NLP vendors for those needing text analytics.
Two, you are really worried not only about pumping money into a black box which you can’t see, can’t trust, can’t understand and can’t control — you are also fearful of taking the plunge. It is expensive and the risk is too high.
Three, you have a problem that never fits “exactly” into a vendor’s NLP toolset, so even though you get some results, customization is also needed right away. Sure, you can pay for customization and sure, you may have the money for such customization, but there is one thing you cannot pay for:
“Confidence the Text Analyzer Can Get Better with Time and Effort”.
That is the current problem with text analytics technologies. It is currently paralyzed by fear.
Enter NLP++.
A Computer Language for Human Language
When a company needs a website, they know they can use a package out there and then customize it to their needs. There is no package that fits a company perfectly. Something has to be customized. Most companies buy a product, and have someone outside the company, such as this west palm beach website design agency, customize it. Alternatively, they might also hire in-house programmers specialized in that tool or language to keep up with the demands of an ever-changing company website.
The same holds true for text analyzers. No matter what text analyzer you buy off the shelf, there has to be customization. The problem in the “Box” model is that they are mostly black boxes, and you can’t hire anyone who can change the black box. The confidence level is very low that the text analyzer will be able to keep up with changing needs, and improve.
It would be ideal if there were a programming language and programming interface (IDE) that would allow anyone (or at least any programmer) 100% access and control of a text analyzer, written like any other computer program. That would give a customer the confidence that they can “see” everything, learn to understand everything, and even make a judgment from the computer code that such a text analyzer is not only feasible, but capable of improving with time. If a new phone number sequence, or new vocabulary, or new slang phrases, or new html formatting, or new OCR errors pop up, then the computer program written for the text analyzer can be modified where needed, giving a customer the confidence that spending money and investing in text analyzers is a worthwhile and even profitable endeavor.
The architects of this technology have been implementing analyzers the same way computer programmers develop computer code to make websites, create and use databases, and analyze data. It is common for most businesses to have in-house teams of IT experts who can handle any bugs or errors encountered in the system. Companies that do not have such a team, however, usually hire companies that provide it support spokane (or wherever they’re located).

Unleashing Levels
One important note in the NLP++ story is that, not only is it a computer language for human language, but it allows for something humans do all the time: communicate between levels of their language understanding.
Humans can use their “world knowledge” to understand that the text “HIIVI” from a document that has been scanned using OCR (Optical Character Recogniztion) software is really the word “HIM” where “M” has been mistakenly changed into an “I”, a “V”, and another “I”. NLP++ allows for marking such a pattern for use further in the processing steps to be recognized as the word “HIM”.
Also, whereas black-box NLP tools normally have a fixed-order sequence of processing levels, NLP++ and VisualText (the NLP++ Graphical User Interface) allow for as many levels (and revisiting, mixing, and inserting levels, or “boxes”) as makes sense for your problem.
In Conclusion
There are many reasons why this technology changes everything when it comes to Natural Language Processing. Of course, there is still a lot of trial and error that needs to go into perfecting this technology, and plenty of Product Concept Test iterations before it becomes usable to customers in all industries.
But the most important reason that NLP++, VisualText, and the conceptual grammar changes the game is because it finally frees companies and programmers from the burden of building or using inflexible tools for the task at hand, so they can program better programs and games or even casino games as the ones you can find at sites like fi.trustpilot.com/review/kasinotilmankierratysta.fi.
This has three implications:
- Confidence that the analyzer works and seeing in detail why it works
- Confidence that the analyzer can constantly improve
- All effort focuses on the analyzer task, rather than fighting with inflexible tools
![]()